Сетевые операционные системы
Планирование
Планирование в Mach в значительной степени определяется тем, что она предназначена для работы на многопроцессорных системах. Так как система с одним процессором является частным случаем многопроцессорной системы, мы сконцентрируем свое внимание на планировании в многопроцессорных системах.
Все процессоры многопроцессорной системы могут быть приписаны к некоторому набору процессоров. Каждый процессор относится точно к одному набору. Таким образом, каждый процессорный набор имеет в своем распоряжении несколько процессоров и несколько нитей, которые нуждаются в вычислительной мощности. В обязанности планирующего алгоритма входит работа по назначению нитей процессорам справедливым и эффективным образом. При планировании каждый процессорный набор представляется замкнутым миром со своими собственными ресурсами и со своими потребителями и является независимым от других процессорных наборов.
Такой механизм предоставляет процессам значительный контроль над своими нитями. Процесс может назначить важную нить процессорному набору, состоящему из одного процессора и не имеющему более ни одной прикрепленной нити, что гарантирует, что эта важная нить будет выполняться все время. Он может также динамически перераспределять нити между процессорными наборами во время их работы, балансируя нагрузку. В то время как средний компилятор обычно не использует этот механизм, система управления базами данных или система реального времени может его использовать.
Планирование нитей в Mach основано на приоритетах. Приоритеты - это целые числа от 0 до 31, причем 0 соответствует наивысшему приоритету, а 31 - самому низшему. Каждой нити присваиваются три значения, влияющих на его приоритет. Первое значение - базовый приоритет, который нить может назначить сама с определенными ограничениями. Второе число - это наименьшее числовое значение, которое может принять базовый приоритет. Третье значение - это текущий приоритет, используемый в целях планирования. Он вычисляется ядром путем прибавления к базовому приоритету значения функции, учитывающей использование процессора нитью в последнюю итерацию.
При использовании второй модели, в которой каждой нити пользователя соответствует одна нить ядра, ядро Mach видит С-нити. Каждая нить борется за процессорное время со всеми другими нитями, независимо от того, к какому процессу относится та или иная нить. С каждым процессорным набором связано 32 очереди готовых к выполнению нитей, по одной для каждого значения приоритета (рисунок 6.4). Совокупность этих 32 очередей называется глобальной очередью процессорного набора. С каждой глобальной очередью связано три переменных. Первая переменная - это мьютекс, который используется для блокирования структур данных глобальной очереди. Он используется для того, чтобы гарантировать, что с очередью в данный момент времени работает только один процессор. Вторая переменная является счетчиком количества нитей во всех 32 очередях. Третья переменная-ссылка содержит указание о том, где найти наиболее приоритетную нить. Она позволяет искать наиболее приоритетную нить, начиная с некоторого уровня, не просматривая все пустые очереди наверху.
Помимо глобальной очереди, каждый процессор имеет свою собственную локальную очередь, в которой находятся нити, постоянно приписанные к этому процессору, например, потому, что они являются драйверами устройств ввода-вывода, которые закреплены за этим процессором. Эти нити не стоит помещать в глобальную очередь, так как они могут выполняться только на одном определенном процессоре.
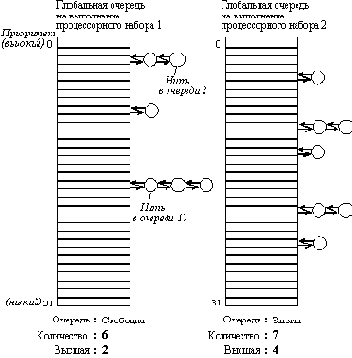
Рис. 6.4. Глобальные очереди на выполнение
для ситуации с двумя процессорными наборами
Основной алгоритм планирования заключается в следующем. Когда нить блокируется, завершается или исчерпывает свой квант, процессор, на котором она выполнялась, прежде всего просматривает свою локальную очередь, на предмет того, есть ли в ней какие-либо нити. Для этого анализируется счетчик нитей, связанный с этой очередью. Если он не равен 0, процессор начинает искать наиболее приоритетную нить, начиная с очереди, указанной в переменной-ссылке. Если локальная очередь пуста, такой же алгоритм применяется для глобальной очереди, с той разницей, что глобальная очередь должна быть заблокирована перед тем, как начать выполнять поиск.
Если ни в одной очереди нет готовых нитей, то запускается и выполняется специальная нить для простоев до тех пор, пока не появится какая-нибудь готовая нить.
Если готовая нить обнаружена, то она получает возможность выполняться в течение одного кванта. По завершении кванта, обе очереди - локальная и глобальная - просматриваются, чтобы узнать, нет ли еще нитей с таким же или более высоким приоритетом, с учетом того, что все нити из локальной очереди имеют более высокий приоритет, чем нити в глобальной очереди. Если подходящий кандидат найден, то происходит переключение нити. Если нет, то активная нить выполняется еще в течение одного кванта. Нить может быть также вытеснена. На многопроцессорной системе длина кванта может быть переменной, в зависимости от числа нитей, которые готовы к выполнению. Увеличение числа готовых нитей и уменьшение числа процессоров укорачивает квант. Такой алгоритм дает хорошее время ответа для коротких запросов, даже если система сильно загружена, и обеспечивает высокую эффективность (длинный квант) для мало загруженных систем.
При каждом тике таймера процессор наращивает приоритетный счетчик текущей нити на небольшую величину. Чем больше становится значение приоритета, тем ниже приоритет нити, и нить в конце концов перемещается в очередь с самым большим номером, то есть с самым низким приоритетом.
В некоторых приложениях над решением одной проблемы работает большое количество нитей, поэтому для них важно иметь возможность управлять планированием в деталях. Mach предоставляет нитям дополнительное средство управления планированием (кроме процессорных наборов и приоритетов). Таким средством является системный вызов, который позволяет нити снижать свой приоритет до абсолютного минимума в течение указанного количества секунд. Это дает возможность выполняться другим нитям. После того как указанный интервал истечет, приоритету возвращается его прежнее значение.
Этот системный вызов имеет другое интересное свойство: он может назвать своего наследника, если захочет.Например, после отсылки сообщения другой нити посылающая нить освобождает процессор и требует, чтобы следующей выполнялась нить-получатель. Этот механизм, называемый планированием с передачами, минует все очереди. Если его использовать с умом, то можно повысить производительность. Ядро также использует этот механизм при некоторых обстоятельствах в качестве оптимизации.
Ядро Mach может быть сконфигурировано так, чтобы реализовывать так называемое аффинное планирование, но обычно такая опция не устанавливается. Когда она установлена, ядро планирует нить на процессор, на котором эта нить последний раз выполнялась в надежде на то, что часть ее адресного пространства все еще сохранилась в кэше данного процессора. Аффинное планирование применимо только для многопроцессорных систем.